I’ve been a big proponent of Jing for screencapture for a while. I still love it, and it’s top notch for sharing video, but I’ve come to enjoy a free tool called Gyazo for screenshots. Both of these tools are invaluable when it comes to web development QA.
Both Jing and Gyazo provide hosting for you (infinite, eternal store, as far as I’ve seen), and they both automatically copy the url to your clipboard. Gyazo is a bit quicker for images, and also doesn’t have a business model, which is comforting. :)
And it’s cross-browser as long as you don’t mind some Japanese text:
CSS hacks to target specific browsers stay where the rest of your styles are, but they certainly don’t validate. For sometime now, the standards community has rallied around conditional stylesheets as a solution to the validation problem.
There are a few problems with it though:
Conditional stylesheets mean 1 or 2 additional HTTP requests to download
As they are in the the <head>, the rendering of the page waits until they’re totally loaded.
Also - Yahoo’s internal coding best practices do not recommend conditional stylesheets
It can separate a single CSS rule into multiple files. I’ve spent a lot of time wondering “Where the eff is that rule coming from!?” when it turned out to be tucked away in a conditional stylesheet.
Using the same conditional comments, we’re just conditionally adding an extra class onto the html tag. This allows us to keep our browser-specific css in the same file:
Doug Avery of Viget points out he prefers to use this technique on the HTML tag, freeing the body tag for dynamic classes. That works just fine. I later changed all my sites to use it on HTML instead of body, actually… Also it combo’s really well with the Avoiding the FOUC v3.0 technique as well as Modernizr.
You fancy something different?
2010.05.07: Oh sheesh ya’ll. Mat Marquis pointed out the code would leave a page <body>-less in IE10, etc. (Well not really because IE would auto-construct a body tag, but anyway…) Some gt later and we’re good.
2010.05.20: Turns out IE conditionals around css files for IE6 can slow down your page load time in IE8! Crazy, right? The solution here avoids that, as does forcing IE to edge rendering.
2010.06.08: And then… Rob Larsen points out that when these conditional classes are applied to the HTML element, it doesn’t block. No empty comment necessary. I think that’s a new winner.
2010.09.07: Update follows!
Throw it on the html tag
Here is the new recommendation, and the one that’s in use in the HTML5 Boilerplate.
It avoids an empty comment that also fixes the above issue.
CMSes like Wordpress and Drupal use the body class more heavily. This makes integrating there a touch simpler
It doesn’t validate in html4 but is fine in html5. Deal with it.
It plays nicely with a technique to kick off your page-specific javascript based on your markup.
It uses the same element as Modernizr (and Dojo). That feels nice.
I left an empty class in there because you’ll probably be putting a no-js in there or something else. If not, delete.
Also if the extra comments around that last tag look weird to you, blame Dreamweaver, which chokes on normal !IE conditional comments.
This solution tends to encourage developers to largely ignore IE during development, and just hack it into submission at the end. That’s actually the worst thing you can do when writing your CSS, because it will force you to use hacks or workarounds that aren’t necessary. Many hacks and workarounds can be avoided by just coding things to work in IE from the start.
If you test IE early in development, you should do your best to use good, standards-compliant code that is optimized for performance and future maintenance. Style forking creates code that’s less optimized in both those areas. Although IE can often be difficult to work with, it is possible to get it to work in most circumstances using good code – it just takes some forethought.
It’s very smart.
In reply to his post I said..
When you are addressing IE’s inconsistencies, attempt to first fix them without singling out IE in particular. In many cases, this is a matter of adding a width or height.. or some overflow:hidden. In general, being more explicit about how the element should appear helps IE6 and IE7 greatly.
2011.04.11: The HTML5 Boilerplate community dug into this and figured out a lot more details around the syntax. Hopefully I’ll get a chance to update this post with those learning, but until then.. click through!
2011.05.18: Updated the main snippet to match the syntax tricks we used in h5bp. See above link for more crazy details.
2011.09.02: Starting a list of languages this technique has been ported to
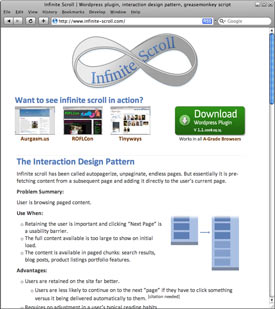
Today I’m releasing www.infinite-scroll.com. Essentially infinite scroll is using ajax to pre-fetch content from a subsequent page and add it directly to the user’s current page. If you have no idea what I’m talking about, you should scroll down to the bottom of aurgasm.us, roflcon.org, or blog.molecular.com.
There is a full design pattern explanation describing when to use it, and considerations to think about when implementing. I also wrote a history of infinite scroll, to cover the history of this somewhat new ajax-enabled interaction technique.
But most importantly, there are two software releases in here:
The Infinite Scroll Wordpress plugin
Enable your wordpress blog with infinite scroll functionality without knowing any javascript. You just need to know css selectors. And no theme php changes should be required to use.
The Infinite Scroll jQuery plugin
Enable anything! Obviously this is for javascript developers only, but it should give you enough flexibility to utilize in your own application.
Since this is a development-focused blog, you may ask…
How is it done?
There is a little known feature in the .load() method that lets you specify the CSS selector of the html you want to include. jQuery will load in any local URL, then parse the html and grab only the elements you’ve defined with your selector. This allows for some pretty fun shit: client-side transclusions (a la purple include) ; and some really kickass shit when you combo it with a local php proxy.
This is really the meat of the code:
1234
// load all post divs from page 2 into an off-DOM div$('<div/>').load('/page/2/ #content div.post',function(){$(this).appendTo('#content');// once they're loaded, append them to our content area});
So the infinite scroll plugin basically leverages that load() method at its core. It’s basically scraping your existing page structure, which means you don’t need to code any custom backend stuff to enable this functionality! Booyah, right?
The rest of the code maintains the status of the ajax call, dies when it finishes going through your pages, and show/hides the loading notification. Please take a look and let me know what you think!